Modeling Timing Structure in Multimedia Signals
Multimedia Timing Structure Model
Measuring dynamic human actions such as speech and music performance with multiple sensors, we can obtain multimedia signal data. We human usually sense/feel cross-modal dynamic structures fabricated by multimedia signals such as synchronization and delay.
The cross-modal timing structure is also important to realize multimedia systems such as human computer interfaces (e.g., audio-visual speech recognition systems) and computer graphics techniques that generate some media signal from another (e.g., lip sync to input speech).
Although the existing methods, such as coupled hidden Markov models, enable us to represent frame-wise co-occurrence of cross-media relations, they are not well suited to describe systematic and long-term cross-media relations. For example, an opening lip motion is strongly synchronized with an explosive sound /p/, while the lip motion is loosely synchronized with a vowel sound /e/.
To represent such mutual dependency among multimedia signals, we propose a novel model based on Interval Hybrid Dynamic Systems (IHDS). For each media signal sequence in multimedia data, we first apply IHDS to obtain the interval sequence respectively. Then, by comparing intervals of different media signals, we construct a multimedia timing structure model, which is a stochastic model to describe temporal structures across multimedia signals (Figure 1).
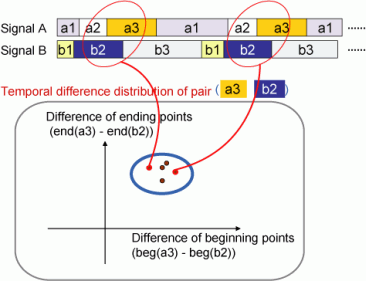
.Figure 1. Learning a Multimedia Timing Structure Model
Media Conversion: from Audio to Video
To evaluate the descriptive power of the proposed timing structure model and the performance of the media conversion method, we conducted experiments on the lip video generation from an input audio signal.
A continuous utterance of five vowels /a/,/i/,/u/,/e/,/o/ (in this order) was captured using mutually synchronized camera and microphone. The utterance was repeated nine times (18 sec.). Using the extracted audio and visual feature vector sequences, we estimated the number of dynamics and their parameters. Then, we computed the timing structure model from the interval sequences partitioned by linear dynamics (the first and second row in Fig. 2).
Based on the estimated model, we converted the audio signals into lip motion video via interval-based representation (the third, forth, and fifth row in Fig. 2). From the comparison with the original video data (the bottom of Fig. 2), we see that the timing of the motion is quite similar to the original one. We also quantitatively examined the generation error from the original training data by comparing to auto-regression models, and verified the proposed method provide the smallest error.
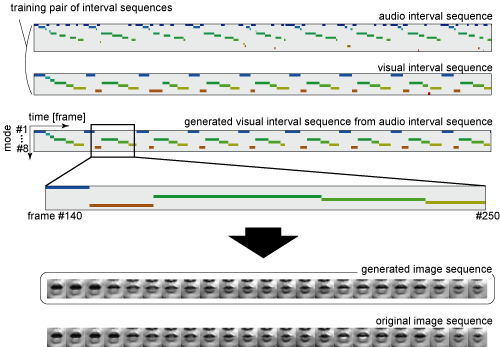
Figure 2. Media Conversion.
Applications of the Multimedia Timing Structure Model
Although this is a preliminary result of evaluating the proposed timing models, its basic ability for representing temporal synchronization is expected to be useful for wide variety of areas. For example, human machine interaction systems including speaker tracking and audio-visual speech recognition, computer graphics such as generating motion from another related audio signals, and robotics such as calculating motion of each joint based on the events in the environment.
Referensces
- [PDF] Chapter 5: Modeling Timing Structures in Multimedia Signals, Doctoral Dissertation, 2007.
- [PDF] Hiroaki Kawashima, Kimitaka Tsutsumi, and Takashi Matsuyama, "Modeling Timing Structure in Multimedia Signals", Forum on Information Technology (FIT2006), Vol.3, pp.93--96, 2006 (in Japanese) (FIT Young Researchers Award).
- [PDF] Hiroaki Kawashima, Kimitaka Tsutsumi, and Takashi Matsuyama, "Modeling Timing Structure in Multimedia Signals", 4th International Conference on Articulated Motion and Deformable Objects (F. J. Perales and R. B. Fisher (Eds.): AMDO 2006, LNCS 4069), pp. 453--463, 2006.