Facial Expression Description, Generation, and Recognition Based on Timing Structure in Faces
Facial Score: Timing-Based Facial Motion Description
In human communication, facial expressions carry fine-grained information because the expressions can be considered as being generated based on two mechanisms: (1) emotional expression produced by spontaneous muscular action and (2) intentional display to convey some intention to others. To recognize human emotion and intention from facial expressions, therefore, the analysis of their dynamic structures is required. However, since most of the existing approaches depend on the Facial Action Coding System (FACS), which concentrates on describing emotional expressions (anger, happiness, sadness, disgust, etc.), and exploit the combination of "action units" rather than dynamic characteristics of facial expressions such as duration lengths and temporal differences among motions.
To extract such dynamic characteristics of faces, we propose a novel description of facial motion, which we named "facial score", that can be acquired by applying Interval-based Hybrid Dynamical Systems (IHDS) to video data of human faces (see the bottom row of Figure 1):
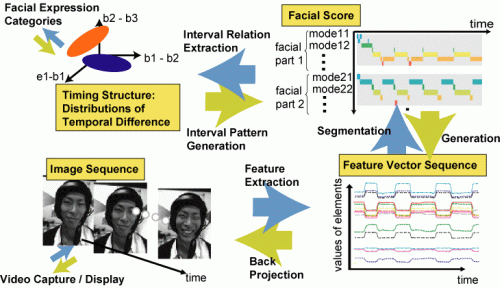
Figure 1. Flow of facial expression recognition and generation exploiting Facial Scores.
Automatic Acquisition of Facial Scores
The automatic acquisition process of facial scores is as follows:
- Extract and track each facial part: eyes, eyebrows, mouth, and nose. As a result, the motion of each part is described by a multivariate vector sequence; each vector represents a shape of the part at time.
- Apply IHDS to each sequence to obtain an interval sequence, which describes the dynamic structure of that part motion. Note that we assume IHDS has been identified beforehand using training data.
- Align along the common temporal axis the group of interval sequences obtained by the above process. Consequently, we obtain a facial score (the top right of Figure 1), which is similar to a musical score in terms of describing timing of elements (notes).
Once a facial score is obtained by the learning process of IHDS, we can activate IHDS to generate facial expression video just like as playing music according to a musical sore (down arrow at the right column in Figure 1). Figure 2 shows an example of the full set of the facial score that describes dynamic characteristics of all facial parts during intentional smiles. The bottom of Figure 2 shows the generated facial motion by activating IHDS; that is, each of constituent dynamical systems, which represents a simple motion, in IHDS is activated based on the facial score.

Figure 2. Facial expression generation using a acquired Facial Score.
Facial Expression Recognition Based on Facial Scores
Figure 2 also suggests that the movement of each smile can be segmented into intervals based on the following four modes: two stationary modes ("neutral" and "smiling") and two dynamic modes ("onset'" and "offset" of smiling). Comparing onset and termination timing of these intervals of different facial parts, we can extract various temporal features that can be used to classify facial expressions (top left in Figure 1).
luation showed that the rate of the correct discrimination ranges from 79.4% to 100% depending on subjects (Figure 3). The performance evaluation showed that the rate of the correct discrimination ranges from 79.4% to 100% depending on subjects.
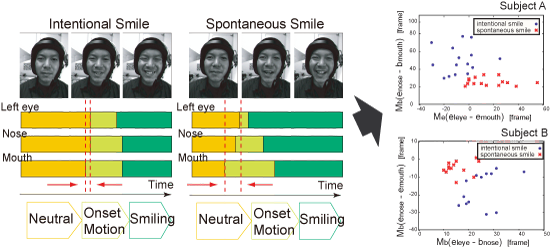
Figure 3. Discremination of Intentional and Spontaneous Smiles
References
- [PDF] Chapter 4: Analysis of Timing Structures in Multipart Motion of Facial Expression, Doctoral Dissertation, 2007.
- [PDF]Masahiro Nishiyama, Hiroaki Kawashima, Takatsugu Hirayama, and Takashi Matsuyama, "Facial Expression Representation based on Timing Structures in Faces", IEEE International Workshop on Analysis and Modeling of Faces and Gestures (W. Zhao et al. (Eds.): AMFG 2005, LNCS 3723), pp. 140-154, 2005.
- [PDF]Hiroaki Kawashima, Masahiro Nishiyama, Takashi Matsuyama, "Facial Expression Description, Generation, and Recognition based on Timing Structure", Information Technology Letters (FIT2005), pp.153-156, 2005 (in Japanese) (Funai Best Paper Award).
- Masahiro Nishiyama, Hiroaki Kawashima, Takashi Matsuyama, "Facial Expression Recognition Based on Timing Structure in Faces", IPSJ SIG Technical Reports, Vol.2005, No.38, pp.179-186, 2005 (in Japanese) (Bachelor's Thesis Award).