マルチメディア信号におけるタイミング構造のモデル化
マルチメディア・タイミング構造モデル
人間のしぐさ・行動を推定し,適切な情報をタイミングよく提示するには,カメラやマイクといった複数センサから得られるマルチメディア時系列信号を統合して動的な状況を認識すると共に,適切なタイミング・メディアによって応答を生成する技術が必要となる.こうした動的マルチメディア情報認識・生成の基盤技術として,本研究では,異なるメディア信号間に存在する時間的相互依存性(マルチメディア・タイミング構造)を表現するための計算モデルを構築した.さらに,学習されたタイミング構造モデルを用いることによって,あるメディア信号から,それとタイミングが合った他のメディア信号を生成するアルゴリズムを開発した.
具体的には,まず各センサから得られた個々のメディア信号を,ハイブリッド・ダイナミカル・システムを用いてそれぞれ分節化し,各メディアの区間系列を求める.つぎに,異なるメディアから得られた区間系列を比較し,時間軸上でオーバラップが存在する区間対の時間関係を,区間の開始時刻の差,終了時刻の差によって表現する.こうした区間対の持つ相互依存的タイミング特徴量は,区間の開始・終了時刻の差をそれぞれ縦・横軸とする2次元のユークリッド空間中の一点として表される.例えば,発話における口元の動きと音声信号の場合,ある動きの区間(口が開く,横に広がるなど)と,ある音声の区間(/a/や/i/)との間の相互依存的タイミング構造は,口元の映像と音声信号とを同時計測し,分節化された区間系列対を学習データとして用いることで,2次元空間中の分布として表すことができる(図1).
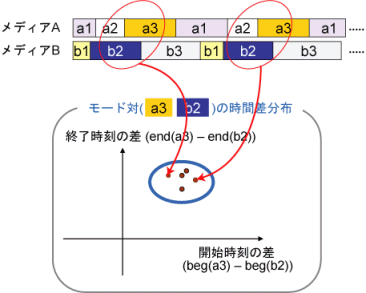
図1. タイミング構造モデルの学習
メディア変換: 音声から唇映像へ
本研究では,このようにして学習されたマルチメディア信号における相互依存的タイミング構造を用いれば,新たに入力された音声信号からそれと同期した口の動き映像が生成できることを示し,モデルの有効性を実証した(図2).このとき,元の(別途撮影された)口映像とシステムが生成した口映像との誤差は,フレームを単位として音声−映像両信号の共起性をモデル化して映像生成を行った場合に比べ,大幅に小さくなることを確認した.
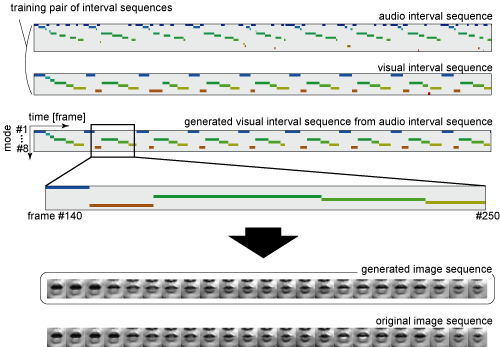
図2. 音声のメディア変換による生成映像と元映像
今後の発展
あるメディア信号から別のメディア信号を生成する技術は,「間合いの取れた」発話や情報提示のタイミング制御に応用することが可能である.一方,映像・音声信号に加え心拍や血圧,呼吸,脳血流を含めた生体信号を同時に計測し,信号間の時間的相互関係を調べることで,人間の外的な振る舞いと,内的な状態とを結びつけることが考えられる.したがって,本年度の成果を発展させることで,人間と自然な間合いでインタラクションを行うシステムを開発できると期待される.
参考文献
- [PDF] 川嶋宏彰, 松山隆司, "時区間ハイブリッドダイナミカルシステムを用いたマルチメディア・タイミング構造のモデル化", 情報処理学会論文誌, Vol.48, No.12, pp.3680-3691, 2007.
- [PDF] 川嶋宏彰, 堤 公孝, 松山隆司, "マルチメディア信号におけるタイミング構造のモデル化", FIT2006 (第5回情報科学技術フォーラム), Vol.3, pp.93--96, 2006 (FITヤングリサーチャー賞).
- [PDF] Hiroaki Kawashima, Kimitaka Tsutsumi, and Takashi Matsuyama, "Modeling Timing Structure in Multimedia Signals", 4th International Conference on Articulated Motion and Deformable Objects (F. J. Perales and R. B. Fisher (Eds.): AMDO 2006, LNCS 4069), pp. 453--463, 2006.