ハイブリッドシステムによる視聴覚モダリティの情報統合
口元の動きと音声とのタイミング構造に基づく音声解析
非定常な雑音環境や複数話者の同時発話がある状況において,情報システムによる音声対話や対話分析・支援を行うには,(A)話者検出,(B)発話区間同定,(C)発話分離という要素技術が不可欠である.本研究ではこれらを高精度に実現することを目的として,口元の動きと音声との詳細な時間同期構造に注目した,新たな発話解析手法を構築する.本手法は,力学系(微分方程式系)と離散事象系を統合した数理モデルであるハイブリッドシステムを用いることで,両信号間の詳細な時間同期構造モデルを統計的に学習するという特徴を持つ.
話者検出
複数人物が存在するシーンに対して話者検出や発話区間検出を行うには,たとえばマイクロホンアレイによる音源定位と人物位置推定とを統合する手法が提案されている.しかし,音源定位の分解能以上に人物が近接している状況や,検出対象空間でのマイクロホン配置の制約によって,検出が困難となる状況がしばしば存在する.このような状況でも高い精度で発話状態を認識するためには,人や音源の位置情報だけではなく,人の発話における口唇動作と音声変化の間の共起性を利用する方法が考えられる.たとえば視聴覚情報を統合した音声認識では,特徴抽出時のフレームを単位として,同一フレームや隣接フレームでの共起性や特徴量相関をモデル化する.ところが,/pa/などの破裂音の発声では口唇動作と音声の開始時刻がほぼ一致するのに対して,/a/などの母音では口唇動作の方が音声よりも先行するといったように,これらは必ずしも完全に同期するものではない.実際,人の発話知覚時にも視聴覚刺激間の時間的なずれがある程度許容されることが知られており,従来手法ではこのようなずれを伴う共起性を十分表現できないという問題がある.
本研究ではこの点に着目し,モード切替型のハイブリッドシステム (switched-mode hybrid dynamical system) を用いることで,口唇動作と音声変化の間の系統的時間差を伴う時間的構造(タイミング構造)を直接的にモデル化し,これにより,映像中の話者を高精度に検出する手法を開発した.具体的には,図1に示すように,学習時にはハイブリッドシステムによって各メディア信号を分節化しておき,得られた時区間の間のタイミング構造を分布として推定しておく.認識時には,学習時に得られた分布を用いて,新たに入力された口元の動きと音声の信号対を評価することで,各時刻における話者を決定する.
非発話者にも口の動きがある状況を設定して比較評価を行った結果,同一フレームもしくは隣接フレームの共起性に基づくモデルに比べ,提案手法ではより高精度に話者検出を行うことが可能であった(話者検出例を図2に示す).本手法は,人物同士が非常に近接している場合や,カメラとマイクが各1台のみの状況でも適用可能であり,遠隔会議システムでの話者追跡による自動撮影だけでなく,アーカイブ化された映像コンテンツの分析などへの応用が期待できる.

図1. ハイブリッドシステム対による話者検出


図2. 話者検出例
音声推定・分離(雑音抑制)
視聴覚統合による音声認識は,従来,音声特徴と口元の動き特徴とを対等なものとして扱ってモデル化する場合が多く,認識時には視覚・聴覚情報のうち信頼性の低い情報に低い重みを与えて統合することで,音声や視覚情報を単独で用いるよりも高い認識精度を実現する.たとえば,入力される音響信号は雑音と音声とが重畳した信号であり,音声のSN比が小さくなるほど,音声側に低い重みを設定する.しかし音声のSN比がある程度小さい場合,その識別精度が視覚情報に主に依存することになる.つまり,音響情報側の切り捨てが行われ,聴覚情報が有効に利用されないことになる.
そこで本研究では,視覚情報は,雑音が重畳した音響信号から音声信号(音声特徴系列)を拾い上げるためのあくまで手掛かりとして利用するというアプローチをとる.特に,コンピュータビジョンの手法によって話者の口形状は(遮蔽がない限りは)精度よく追跡できる(図3).すると図4で示すような「口元の動きから音声を生成する機構」を積極的に利用した音声推定が可能となる.ただし,これには口元の動きから精細な音声を生成できる機構が必要であり,1で述べたように,口元の動きと音声との詳細な対応関係が求められるため,従来は困難であった.この問題を解決するために,図5に示す方法を取る.まず上述の話者検出と同様のハイブリッドシステム対により,両信号間の詳細な時間同期構造をモデル化する(ただし特徴量はより詳細なものを用いる).すると,話者をカメラで撮影して得られた口元の映像からそれに対応する音声候補を複数生成することができる.生成されたこれらの候補と,実際に観測された音響信号との整合性を,パーティクルフィルタに基づく手法で評価することで,非定常環境下での高精度な発話分離・音声推定を実現できる.図6にその比較結果を示す.
なお,口元の動きや音声,さらにそれらの間の対応関係は個人差が大きいため,本研究では,個々の利用者のデータからあらかじめこれらのモデルが学習できるような状況(特定話者の状況)を前提とする.雑音除去されたクリーン音声の特徴系列は,音声認識エンジンの入力として用いることができるため,今後は音声認識精度の観点から詳細な評価を行う予定である.

図3. 特徴点追跡と口元画像の切りだし例
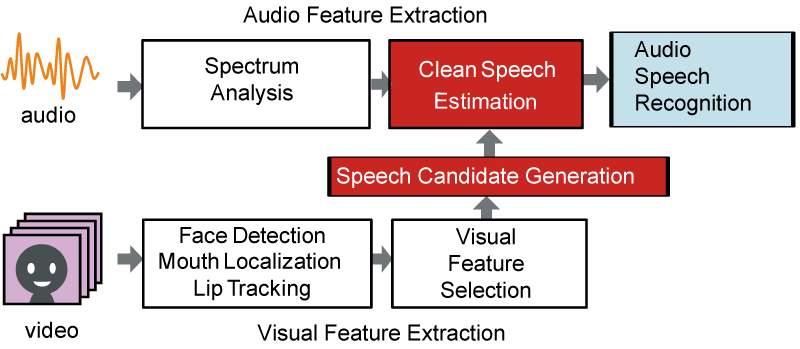
図4. 音声推定の流れ
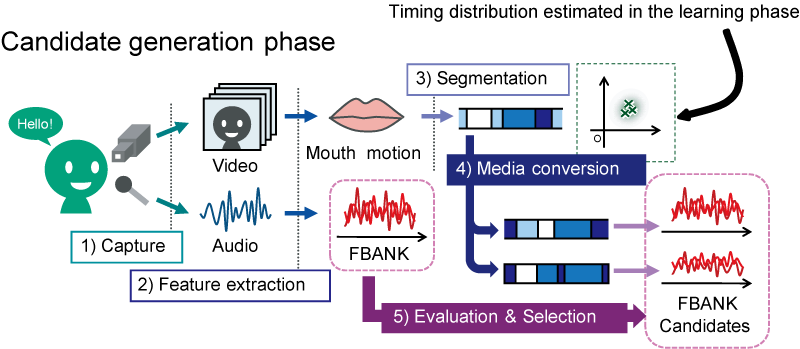
図5. ハイブリッドシステム対による口元の動きからの複数音声候補の生成(学習は図1と同様の方法を用いる)
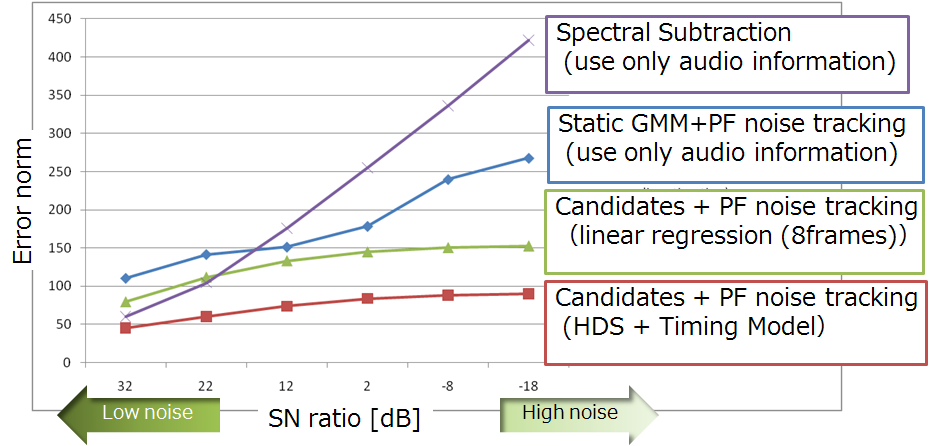
図6. 音声推定の比較評価
参考文献
- [PDF] Hiroaki Kawashima, Yu Horii, Takashi Matsuyama, "Speech Estimation in Non-Stationary Noise Environments Using Timing Structure between Mouth Movements and Sound Signals", Interspeech2010, pp.442-445, 2010.
- [PDF] Hiroaki Kawashima, Takashi Matsuyama, "Interval-based Modeling of Human Communication Dynamics via Hybrid Dynamical Systems", Workshop on Human Communication Dynamics (NIPS WS), 2010.
- 川嶋宏彰, 堀井悠, 松山隆司, "口唇運動-音声間のタイミング構造を利用した非定常雑音環境での発話音声推定", 第13回画像の認識・理解シンポジウム (MIRU), 2010.
- [PDF] Yu Horii, Hiroaki Kawashima, Takashi Matsuyama, "Speaker Detection Using the Timing Structure of Lip Motion and Sound", IEEE CVPR Workshop on Human Communicative Behavior Analysis (CVPR4HB), 2008.
- 堀井悠, 川嶋宏彰, 松山隆司, "口唇動作と音声のタイミング構造に基づく話者検出", 第11回画像の認識・理解シンポジウム (MIRU), pp.193-200, 2008.